
XML Dateien in Loxone auswerten
In der Hausautomatisierungswelt ist man schon leidgeplagt. Alleine wenn man so daran denkt, wie man sich seine Registerinformationen von Geräten zusammensuchen und abfragen muss. Hat man dann strukturierte Daten vorliegen, dann muss man mangels Tools über Mustererkennung unstrukturiert darauf zugreifen und verbringt u.U. viel Zeit beim Erstellen der richtigen Patterns. Einschlägige Fragen, Tipps und Diskussionen in entsprechenden Foren können ein Lied davon singen. Nachdem ich bereits einen JSON Parser für Loxone erstellt hatte, dachte ich mir, dass die rudimentären XML Abfragemöglichkeiten in Loxone ebenfalls nicht wirklich befriedigend sind. Gedacht, getan. Nachstehend findet sich ein XML-Parser für Loxone, der über XPath-ähnliche Abfragen verwendet werden kann. Natürlich wieder mit den Sourcen zum Download (v05).
Für einen IT-ler ist Struktur alles. 🙂 Die Verarbeitungsmöglichkeiten sind jedoch leider oft nicht befriedigend. Zudem möchte ich für eigentlich kleine Anforderungen keine weitere Hardware einsetzen müssen. Als nicht-Besitzer eines Loxberry/RaspPi lag also auch hier der Schwerpunkt darauf, den XML-Parser nativ und ressourcenschonend auf meinem Loxone Miniserver G2 zum Einsatz zu bringen.
Inspiriert durch die verschiedenen XML-Parser im Netz gibt es nun eine picoC Version für Loxone. Bei der Umsetzung bin ich um Jahre gealtert. Aber einer muss sich ja anstrengen, der Ersteller oder der Anwender. Immer besser: der Ersteller. 🙂
Letztlich ist eine Version herausgekommen, die denke ich ganz gut einsetzbar ist.
Neben dem eigentlichen Parsen des XML habe ich noch ein XPath subset für die Adressierung von Werten eingebaut. XPath komplett wäre zu umfangreich und auch nicht zielführend für den Loxone Anwendungsfall. Das Abfragen von Mengen von Werten, nicht wissend welcher Wert an welchem Ausgang liegt, ist in Loxone aus meiner Sicht auch nicht sinnvoll. Die Werte müssen eindeutig adressiert und ausgewertet werden.
Was kann der XML-Parser?
Natürlich XML parsen. Da man hier nichts sieht, ist das zunächst wenig spektakulär, aber eben der Hauptteil des Codes. Sichtbar hingegen ist das Abfragen der Ergebnisse. In Anlehnung an XPath können strukturierte Pfade, Attribut-Werte innerhalb von Elementen oder Arrayindexe angegeben werden. Zu beachten: In Anlehnung an XPath wird das erste Element eines Arrays mit 1 und nicht mit 0 angegeben…
Die Abfragesyntax im Überblick anhand eines Beispielausdrucks:
f:/root/level1[@time='day' @active='true']/level2[@id='3']/value
- Zu Beginn einer jeden Konfigurationszeile steht zunächst die Angabe des auszulesenden Datentyps: i(nt), f(loat), b(ool), s(tring)
- bool-Werte wie true/false oder auch on/off werden zu 1/0 „übersetzt“
- XML-Elemente werden mit „/“ getrennt angegeben
- XML-Attribute innerhalb von Elementen werden über „@“ angesprochen und auf Werte abgefragt. Es können hier auch mehrere Werte angegeben werden.
- Statt der Attributwerte kann im Falle von Mehrfachvorkommnissen auch direkt auf einen Index zugegriffen werden, z.B. „[3]“
- Im Beispielausdruck wird die Zeichenfolge zwischen „value“ gesucht. Also z.B. <value>12.4</value>
- Möchte man einen Attributwert ausgeben, so könnte man im Beispiel statt value einfach @id angeben und würde dann eine 3 erhalten
Am Besten betrachtet man sich das nachfolgende Bild, dann wird schnell klar, wie das Ganze funktioniert. (Beim Draufklicken wird das Bild groß)
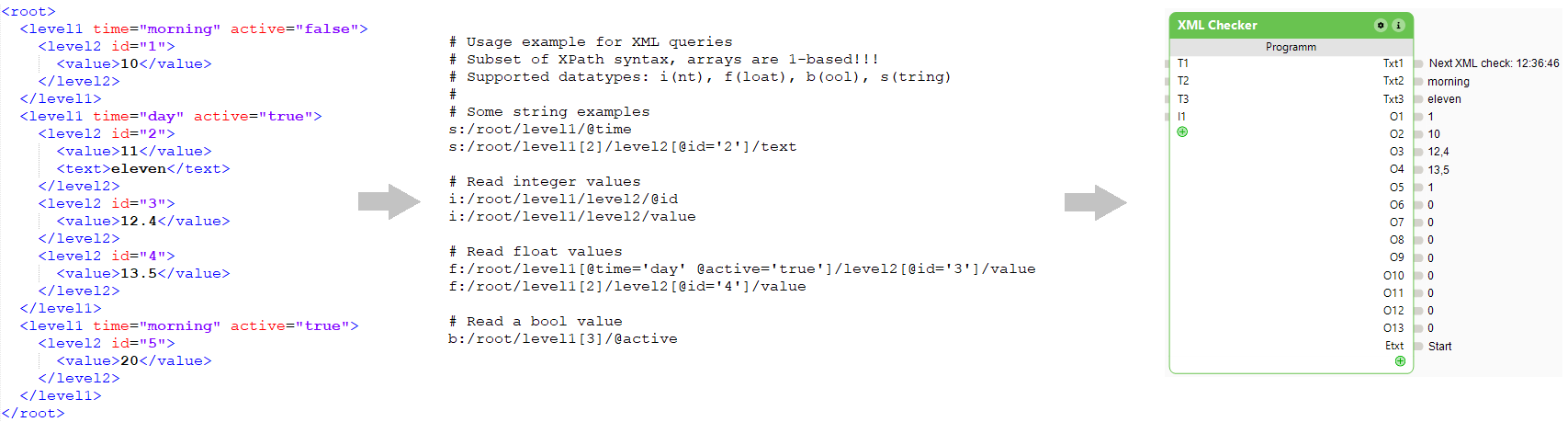
Damit die maximal 13 numerischen und maximal 2 String-Werte auch später noch zugeordnet werden können, kann man in der Konfiguration noch Kommentarzeilen angeben. Diese beginnen immer mit einem Hash (#).
Eine Konfiguration könnte also wie folgt aussehen (Klick auf das Bild macht es groß).
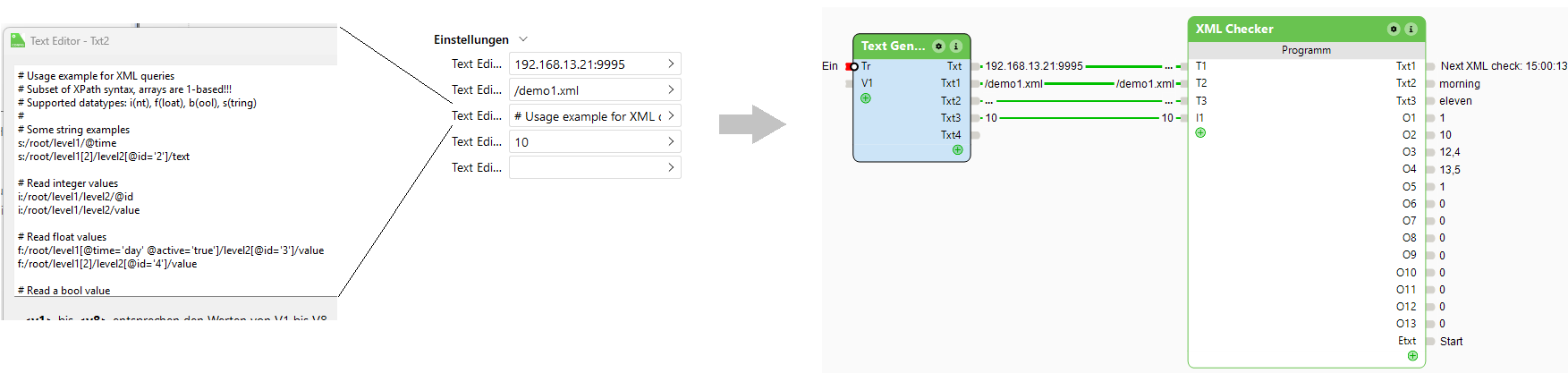
Zum Lesen der XML Daten werden im Textgenerator-Baustein (Tr-Eingangskanal einschalten!) vier Informationen hinterlegt, dann an einen Programm-Baustein angeschlossen und auf dem Miniserver gespeichert. Und schon gehts los…
- IP-Adresse oder Name des abzufragenden Servers und ggfls. noch der Port. Wie bereits beim JSON-Parser ist es auch hier so, dass nur http-Verbindungen genutzt werden können, also kein https. Für viele Anwendungsfälle ist das aber ok.
- Seite, die abgefragt werden soll. Der finale Request, der im Bild konfiguriert ist lautet: http://192.168.13.21:9995/demo1.xml
- Im Texteditor wird die komplette Konfiguration wie oben beschrieben hinterlegt. Daran denken: Es können maximal 2 Textausgänge und 13 numerische Ausgänge genutzt werden.
- Wartezeit in Sekunden (im Bild also 10 Sekunden) bis zum nächsten Check.
Folgende Phasen werden dabei durchlaufen und zur Information auch ausgegeben:
- Abfrage –

- Parsen –

- Statusinfo –
- Warten –

Erwartet bitte keine Wunder. Ein Miniserver bleibt ein Miniserver. Das Parsen von großen Strukturen ist sicherlich nicht sinnvoll auf diesem Device, kann sogar bei zuviel Speicherverbrauch zu Problemen führen. Aber für kleinere Anwendungsfälle ist der Parser durchaus brauchbar.
Wer mag – die Sourcen
Hier der Parser zur Verwendung.
Wie immer gilt: Fortschritt, nicht Perfektion… Feedback ist also jederzeit willkommen. Nachmachen wird nicht empfohlen…